February 21, 2022
How using AI and Text Mining will dramatically reduce the time it takes to buy Protection
Text mining is a new concept which will speed up the process of buying protection. Customers will notice a better experience, particularly at the underwriting stage of their policy. Advisers will welcome the increased speed and accuracy it brings but also how it will make it easier to secure cover for clients with complex medical histories. But in an industry known for its technical jargon we must be careful not to hide these benefits away behind a wall of technobabble.
Let’s face it, all industries are talking about Artificial Intelligence (AI), Augmented Reality (AR) and others are constructing Metaverses and minting non-fungible tokens (NFTs). It’s easy to get excited about the shiny newness of these technical toys and forget to explain to people what the benefit will be to them as consumers.
I’m the Product Manager for the Text Mining product at UnderwriteMe. I’ve worked here for a year and a half now. Before that I’ve been in FinTech for the past 15 years and in the last five years I’ve focussed on AI and how you bring AI products from the pilot stage through to implementing them as production systems – i.e. getting them out to real customers. I realise these subjects are technical and can appear complex and I’ve set myself a goal of explaining text mining simply.
Text mining is one application of Natural Language Processing, which itself is a subset of AI, a general term for machines acting like or interacting with humans. Natural Language Processing is the specific ability for machines to translate content that humans can read into content that machines can read. Text mining is the creation of useful knowledge or insights from that content. I really like the use of text mining within the field of innovation itself.
If you think about it, research reports, patents, articles, blogs, are unstructured data and people are creating more of this type of content every day. As a human it’s close to impossible to keep on top of. So, innovators use text mining to carry out analysis of these articles to uncover the state and evolution of trends in a particular area of innovation. Then they can extract evidence and recommendations about future applications or future directions of innovations.
Financial services companies are already using text mining even though it’s not something we hear talked about much at conferences or events. You can see companies using text mining for reading and understanding the intent of financial contracts. You can see it in customer services for email, triage and routing. And financial research is a wide area where companies are using it. Corporate releases and reports are all now being read by algorithms looking to help spot trends and pick stocks for investments.
From a protection point of view, we ultimately want to help customers experience a quick and fair process when applying for life insurance. But for clients with complex medical histories the application process can be long and drawn out, a poor experience for the customer and a frustrating process for the adviser to manage. We want all customers to have the opportunity to receive the quick and transparent service that automation brings with the knowledge we are assessing their individual situations fairly and accurately.
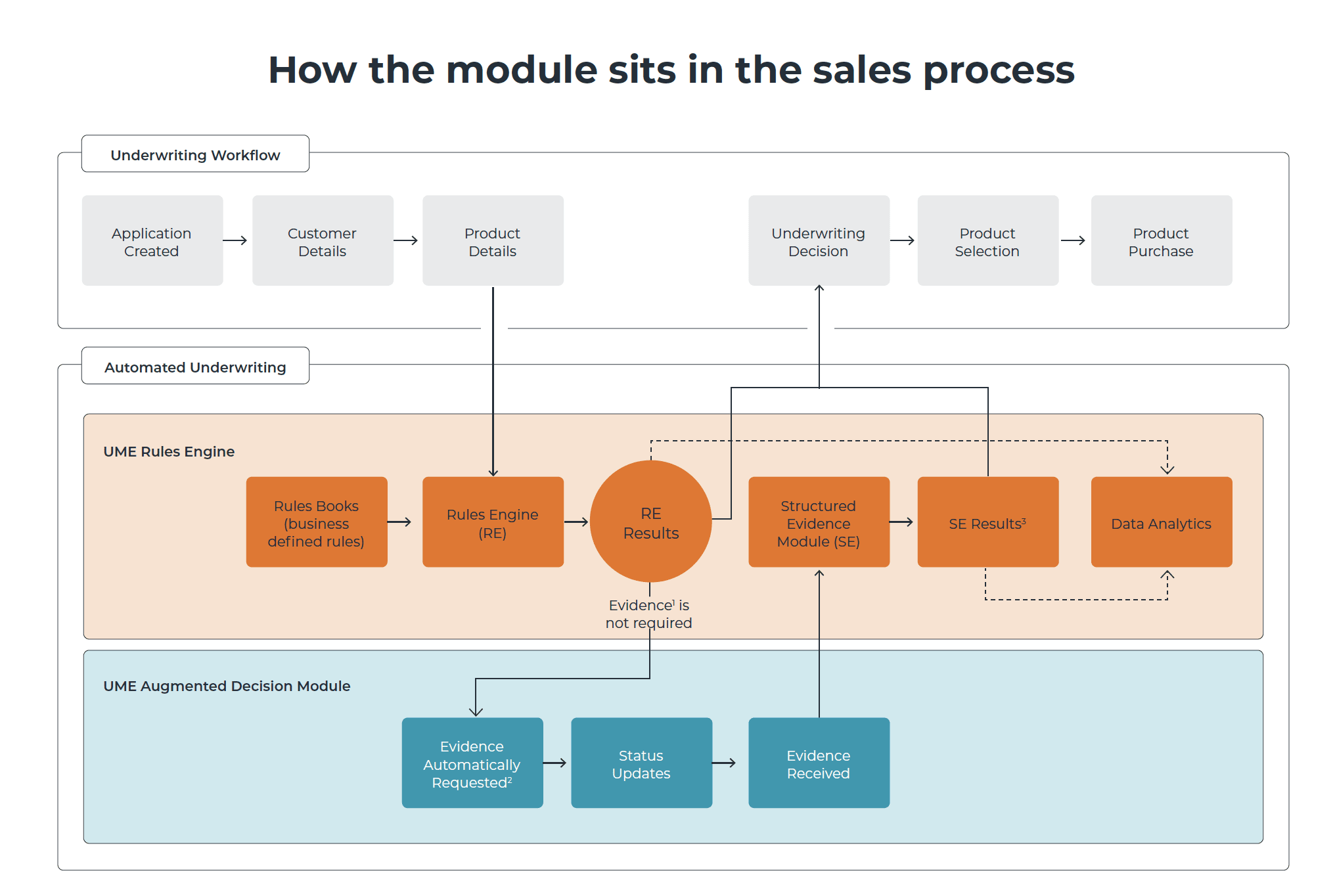
Using data to help with this through automation is key. But when that data is in unstructured formats like medical records, machines can’t read it which means those efficiency and transparency gains brought about by automation are not available to a whole segment of customers who require underwriting based on the medical record. Text mining is the missing piece in the automation
puzzle. It fills the gap that in the past has left customers with complex medical histories having to endure a dramatically different experience when applying for life insurance.
The first step to solving this problem is to make that unstructured data machine-readable, making it structured and coherent. And that’s done by text mining.
At UnderwriteMe, we know that some see underwriting as quite an intrusive process and we’re keen to work on anything that would make the process a better experience for customers. But we also must keep customer trust. Is text mining really up to the to the job in this area? It’s a fair challenge but I would say it’s definitely up to the job.
Innovation in text mining has come a long way in recent years. It’s at a stage where the skill level of natural language processing by machines means that machines can do the cognitive tasks that previously could only be done by humans. And so, reading and understanding medical reports is a challenge that text mining is probably now mature enough to begin to tackle.
So, text mining can help to improve the underwriting process but it’s still relatively unknown. I find that for AI projects, even pilots, are a bit heavyweight because you’re exploring such a modern technology. Doing a large-scale pilot requiring heavy integration investment when y
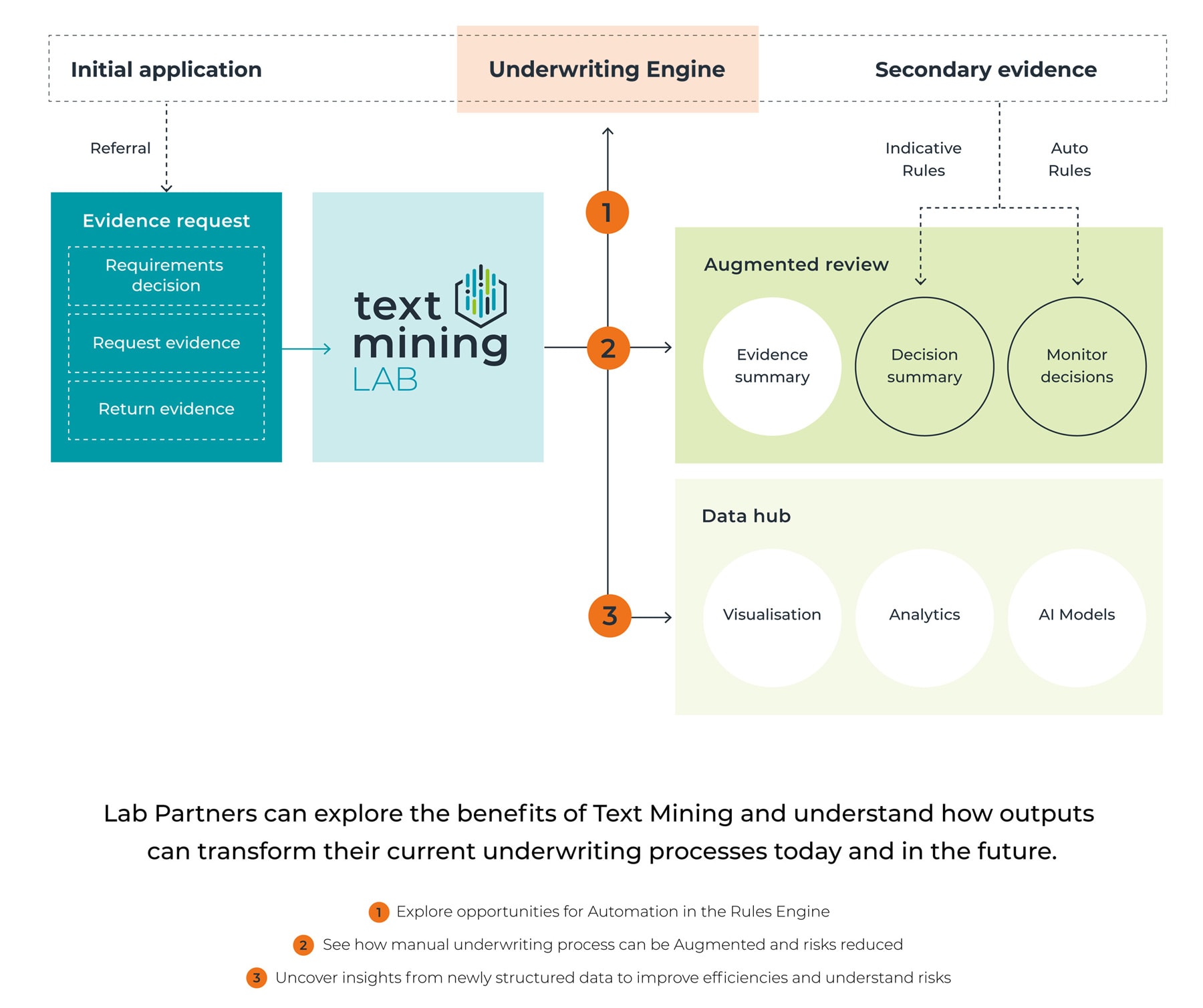
ou may already have resource and financial limits might not be feasible. And how many different approaches do you test? To make it easier for people wanting to have a go, we’ve created the Text Mining Lab where we are encouraging partners to put text mining skills into the hands of many different people in different roles throughout their business to discover where they see the greatest value and to help them measure what impact text mining might have for them in the future.
The lab will help us discover what works for partners and what doesn’t in a very collaborative way. It’s effectively beta access to the text mining skills we’ve developed. Participants at the lab will have access to the lab portal, which allows them to upload the unstructured medical
reports and then receive back the enriched structured data reports.
We also regularly meet with lab partners to help design experiments and to share feedback. It’s meant to be a very lightweight way of testing potential applications across the underwriting and claims customer experience and giving partners the opportunity to test those big ideas in a quick way. The Text Mining Lab is now live in the UK and the US, with plans to extend the lab to include Asia and Australia.
I mentioned earlier that we must be careful about customer trust as data, particularly medical data, is a sensitive area. The sensitivity of the data we are working with is something we need to be water-tight on. When we were designing the Text Mining Lab, lab partners start small with just a handful of anonymised reports, to get them comfortable with the process. We then carry ou
t our own data anonymisation checks to ensure the data is handled in the most sensitive way so that going forward, we can process larger volumes within the lab to support the bigger experiments as necessary.
I’m convinced text mining will make the underwriting process a better experience for customers and advisers in future. As insurers begin to adopt it, we’ll see an increase in straight through applications. In the short term, the insights that Text Mining enables will highlight efficiencies, reduce risks and even help to redefine referral processes for some conditions, reducing the impact o
f the slow and expensive manual processes we face today. In the longer term, Text Mining could close the gap completely and give all customers the same buy now experience.
Whilst it might appear to be a complex subject, it’s actually a simple concept and I’m really excited about developing it further for the benefit of our customers and the industry as a whole.